




条件に一致する最終行の値を関数で抽出する数式の説明2
このページは「条件が合うもののうち最終行の値を抽出する方法」を解説している4ページ目です。
引き続き数式の意味を解説していきます。

5.「LARGE( )」の部分
次は、ここまでの結果を踏まえて「LARGE( )」の部分です。

LARGE関数は、「〇番目に大きな数値を取り出せる」関数で、「〇番目」を指定しているのが「COUNTIF($D$3:$D$12,"A")」の部分です。
COUNTIF関数は「条件に合うセルの数をカウントできる」関数で、ここでは「D列がAのセルをカウント」させています。
つまり、前のページの項目3で説明した、「($D$3:$D$12="A")*1」と同じ条件ですね。
ここでもう一度一覧表を見てください。

表のように、社員Aが行った出張は全部で4回。つまり欲しいのは4番目の出張の情報です。
つまり「条件に合うセルの数=条件に合う最終行の順番(〇番目)」なのです。
そしてLARGE関数で参照しているのは下の枠内のような、配列に格納された値です。
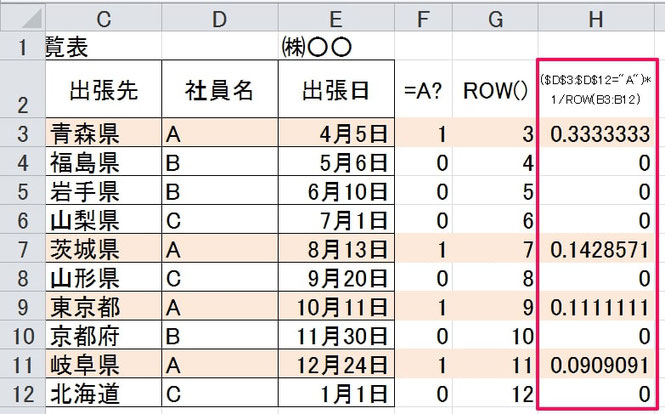
この枠内で4番目に大きい値は、セルH11の「0.0909091」です。
つまりLARGE( )の計算結果は、「0.0909091」となるのです。

6.「MATCH( )」の部分
では次にMATCH( )の部分です。

この内、青下線の部分は先ほど「0.0909091」と述べました。
つまり、実質的には「MATCH(0.0909091,1/ROW(B3:B12),0)」となります。
そしてMATCH関数は、「指定した検査範囲(この計算式では「1/ROW(B3:B12)」を指す)に対して、検査値(この計算式では「0.0909091」)がある順位を返す」関数です。
まず、検査範囲の部分(「1/ROW(B3:B12)」)は次のように計算されます。
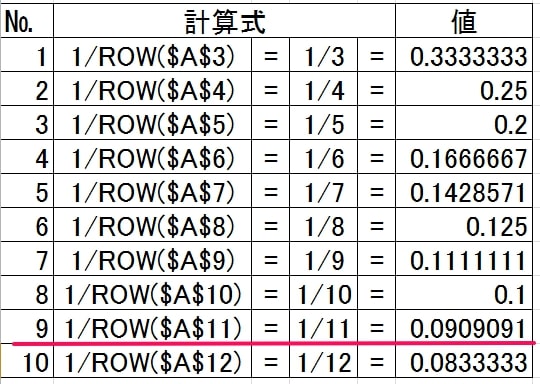
これに対して検査値は「0.0909091」なので、検査範囲の「9番目」となります。
つまり、MATCH( )の部分の計算結果は、「9」となるのです。

7.「INDEX( )」の部分
その次に「INDEX( )」の部分です。

この内、青下線部分は「9」と分かりました。
つまり、実質的には「INDEX($A$3:$E$12,9,COLUMN(B1)」となります。
まず、INDEX関数は「指定の配列(この計算式では「$A$3:$E$12」を指す)に対して、指定した行番号(計算の結果「9」)、列番号(この計算式では「COLUMN(B1)」を指す)にある値を返す」関数です(INDEX関数+MATCH関数の基本を知りたい方はコチラ)。
そして、COLUMN関数は「指定したセルの列番号を返す(例えば「C1」の場合には3列目(A,B,C)を指定しているので「3」)」関数です(COLUMN関数の基本を知りたい方はコチラ)。
つまり「COLUMN(B1)」は「2」となるので、計算式は「INDEX($A$3:$E$12,9,2)」となります。
そして「$A$3:$E$12」において行番号9、列番号2は、「セルB11」なので、INDEX以下の計算結果は「×▲講習」となるのです。


8.まとめ
以上、2ページに渡って計算式を説明しました。
まとめると、一番理解するのに難しいのはLARGE( )の所です。
配列数式が理解できているか?にも繋がりますが、何度か使っているとどうしてこうなるのかが分かってきますので、根気よく使ってみましょう。
参考になれば幸いです。
- 条件に合う最終行抽出 各ページへのリンクはこちら
- ◎具体例の確認(1/4ページ)
- ●計算式の作り方(2/4ページ)
- ◎計算式の解説(前編)(3/4ページ)
- ●計算式の解説(後編)(4/4ページ)